
[Free Script] Checking AIO Snippet in Google SERP
Check what is the frequency of AI Overview for your list of keywords.

A lot of data has been released from multiple platforms like Brightedge and SEOClarity showing what percentage of queries show AIO Snippet on Google.
However, we are not aware of what type of queries they have tested or how many queries. Queries in some niches can be very specific and different.
So I decided to write a Python script to test the set of keywords for which we get traffic. This helped us to gain insights into our specific industry. For example, I got to know that when I enable SGE Labs AIO snippets show up much more often than when SGE Labs are disabled -

So how do we do it?
For this, we cannot use scrapers like Scrapy because it will probably get blocked and will not be able to perform any actions on the page like - searching or clicking on show more button.
For scraping AIO Snippet, we have to -
Make sure we are on a US IP Address (Use VPN if required)
Log in to a Gmail account that can see AIO Snippets (With or without SGE Labs enabled).
Search for the query.
Check if the AIO Snippet is present.
If it is present then click on the “Show More” button
Scrape All the Links and Take a Screenshot
All these steps are possible using - Selenium.
What is Selenium? Selenium is an open-source tool that allows you to automate web browsers. It provides a way to interact with web pages through a variety of web drivers (like ChromeDriver for Chrome, GeckoDriver for Firefox, etc.). With Selenium, you can simulate a real user's interaction with a web page, such as clicking buttons, filling out forms, and extracting information via a script.
Selenium is mostly used for testing purposes, but it has good applications in web scraping as well.
So Initially I used Selenium but Google was able to detect it and did not allow me to log in. So I had to use an Undetected Chrome Driver - which blocks Google from detecting that we are sending automated requests to Google.
However I was facing some issues with running Undetected Chrome Driver in headless mode, so I used Selenium Base in Headless and Undetected mode.
What is Headless Mode? In Headless mode, the web browser runs without a graphical user interface (GUI). So your Chrome browser will be running but you will not be able to see it, which is useful because you want this whole process to run in the background. But if you want to see what’s going on Chrome browser, you can disable headless mode.
So to summarize - We will scrape the AIO snippet from Google Search using Selenium Base in Undetected and Headless mode. So without further ado, let’s jump into the script.
Note: I recommend to read the whole article because there are multiple values you will have to replace in the script to work.
Before we start we need to install some packages - Selenium, SeleniumBase, and Pandas. So run the following commands in your terminal -
pip install selenium
pip install selenium-base
pip install pandasImporting Packages
So we are importing Driver from Selenium Base, and some packages from Selenium to scrape via Class Names and to use Keyboard.
Time for pausing between each query or function. Random for randomizing our waiting time - so that Google cannot understand our patterns.
Pandas for dataframes.
from seleniumbase import Driver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import pandas as pd
import randomReading a CSV file of queries using Pandas, and then converting it to a list.
I have also mentioned some sample queries which most of the times shows AIO Snippet. So you can use them to test first.
df = pd.read_csv(r'query_list.csv',encoding='latin-1')
df = df.replace("/"," ",regex=True)
print(df)
query_list = df['query'].values.tolist()
#test_queries
#query_list = ['what is digital marketing','features of macbook pro m3','write few lines about christmas','what are the properties of metal']
print(query_list[:5])
number_of_queries = len(query_list)Initializing Chrome Driver and setting Google’s login URL to a variable.
Note that here if you do not want to run the Chrome driver in headless mode, you can simply set headless=False.
#path to chromedriver
driver = Driver(uc=True, headless=True)
#login to google manually
google_login_url = 'https://accounts.google.com/v3/signin/identifier?hl=en-gb&ifkv=AaSxoQyH1Qet0VlLGN7HL7CD1zRZkw0dVFB4bXApnkylfeDCW4kx3vmK9HBjvDjfi4a6yi3WFJJfug&flowName=GlifWebSignIn&flowEntry=ServiceLogin&dsh=S1544068279%3A1715766753444785&ddm=0'Login to Google
Following is a function to log in to Google. There are some important points to remember here -
Make sure to create a new Google account or use an alternative one (we all have one), and avoid risking your main account.
Turn off 2FA on the account you are using to avoid verifying every time you run the script.
When you run this script for the first time, do not use Headless mode and verify yourself on your device with US IP.
Once you have done that, next time Google will hopefully not ask for any verification.
Explanation of the below function -
First, we visit the login URL, then we wait for 5 seconds. And then we find the email field and enter the email. Then we again wait for 5 seconds and then enter a password.
It will also print the URL it is on while entering your email and password. If the URL changes after entering the password, it means we are logged in.
If something goes wrong, it will take the screenshot and save it in your folder.
#function to login to google
def login(email,password):
driver.get(google_login_url)
try:
current_url = driver.current_url
time.sleep(5)
# Find and fill in the email input field
email_input = driver.find_element("name", "identifier")
email_input.send_keys(email)
email_input.send_keys(Keys.RETURN)
print('Email Entered')
current_url = driver.current_url
print(f"Current URL: {current_url}")
time.sleep(5)
password_input = driver.find_element(By.NAME, 'Passwd')
password_input.send_keys(password)
password_input.send_keys(Keys.RETURN)
print('Password Entered')
current_url = driver.current_url
print(f"Current URL: {current_url}")
time.sleep(5)
except:
print('Not able to login')
driver.save_screenshot('<PATH TO YOUR FOLDER>/error.png')Search on Google, Click on Show More Button Scrapre Links
The following are functions to
Search on Google by finding the search bar using the class name
Clicking on a show more button which shows up when the AI Overview snippet is available
Scraping the links that are inside the AI Overview Snippet. It also checks if your domain name is available in the AI Overview Snippet. So replace “my_domain_name” with your “domain_name”
#function to search
def search(url, class_name, search_term):
driver.get(url)
input_element = driver.find_element(By.CLASS_NAME, class_name)
input_element.send_keys(search_term, Keys.ENTER)
#function to click on any button
def click_button(class_name):
button = driver.find_element(By.CLASS_NAME, class_name)
button.click()
#function to scrape links
def scrape_links(class_name, query):
links = driver.find_elements(By.CLASS_NAME, class_name)
for j in links:
link = j.get_attribute('href')
query_link = query + '@' + link
all_links.append(query_link)
if 'my_domain_name' in link:
query_link = query + '@' + link
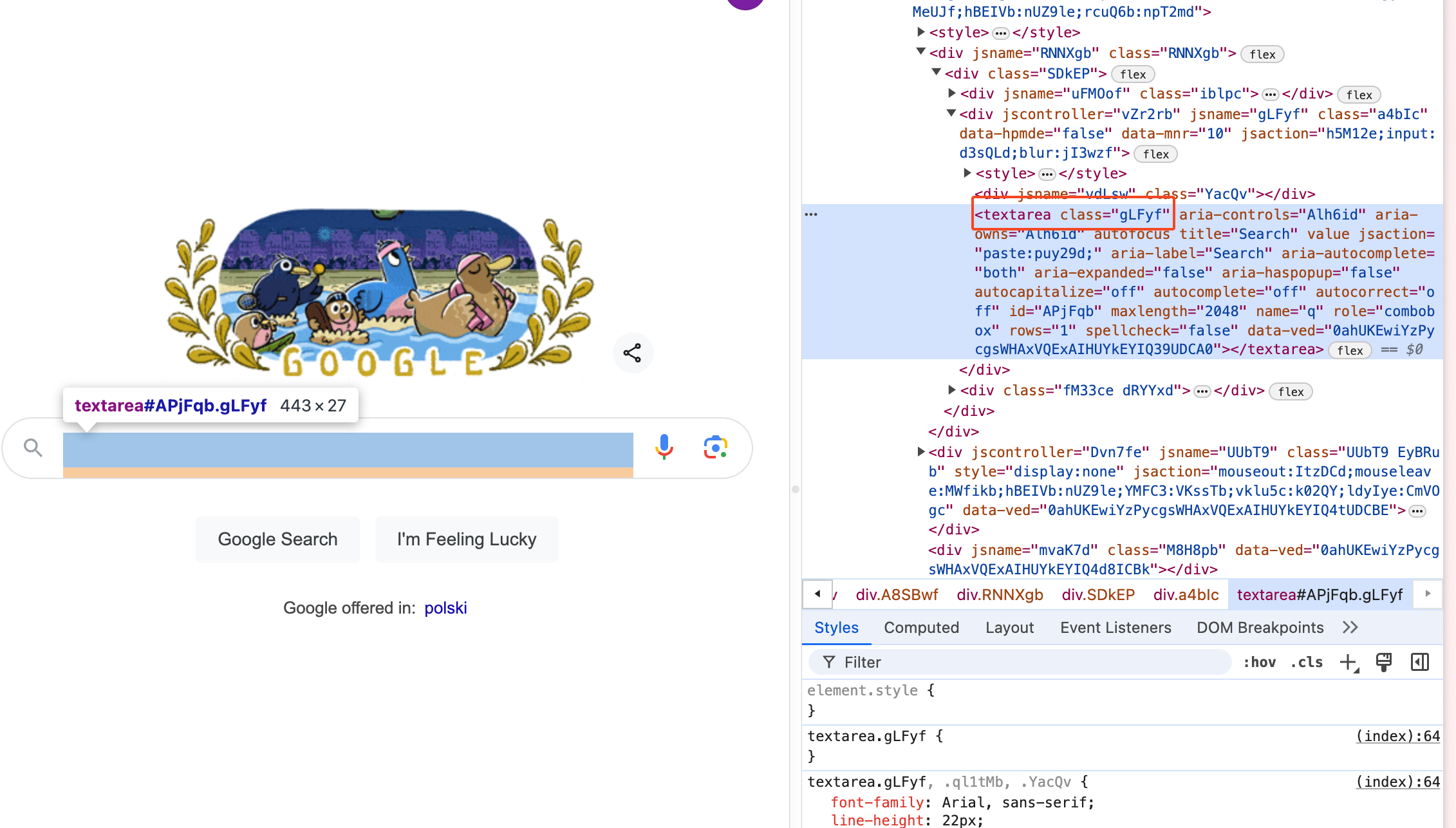
my_domain_link.append(query_link)Note that these Class names can change in the future, so to get the class names in the future, simply right-click on the element and copy the class name.
Declare Variables to store Values, Run Login Function, Selecting terms to Search
Next, we will declare variables to store the values. In the result we will store the status of whether AI Overview is visible or not, then we will check if our domain link is available or not and store it inside my_domain_link, then all the links get stored inside all_links, and queries we are searching for will be stored inside queries variable.
Then we run the function of login. Here you have to replace the placeholders with your actual account credentials.
Then we define the Google URL, we are adding parameters of Country and Language just to be sure we are seeing US Search results.
And then we will define the search terms to find on the page. So, initially, when AIO was in beta, multiple terms and phrases were showing up above AI Overview. But now there is just one term - “AI Overview”. In the future, if these terms change, you can alter them to the latest ones.
#declare variables to store the values
result = []
my_domain_link = []
all_links = []
queries = []
login('email_id','password') #replace with your email and password
url_to_visit = 'https://www.google.com/?gl=us&hl=en'
#search_terms
search_term_0 = 'AI Overview'
# search_term_1 = 'Generative AI is experimental'
# search_term_2 = 'AI overviews are experimental'
# search_term_3 = 'Get an AI Overview for this search?'
# search_term_4 = 'overview is not available for this search'
# search_term_5 = 'Try again later.'
search_term_6 = 'Our systems have detected unusual traffic'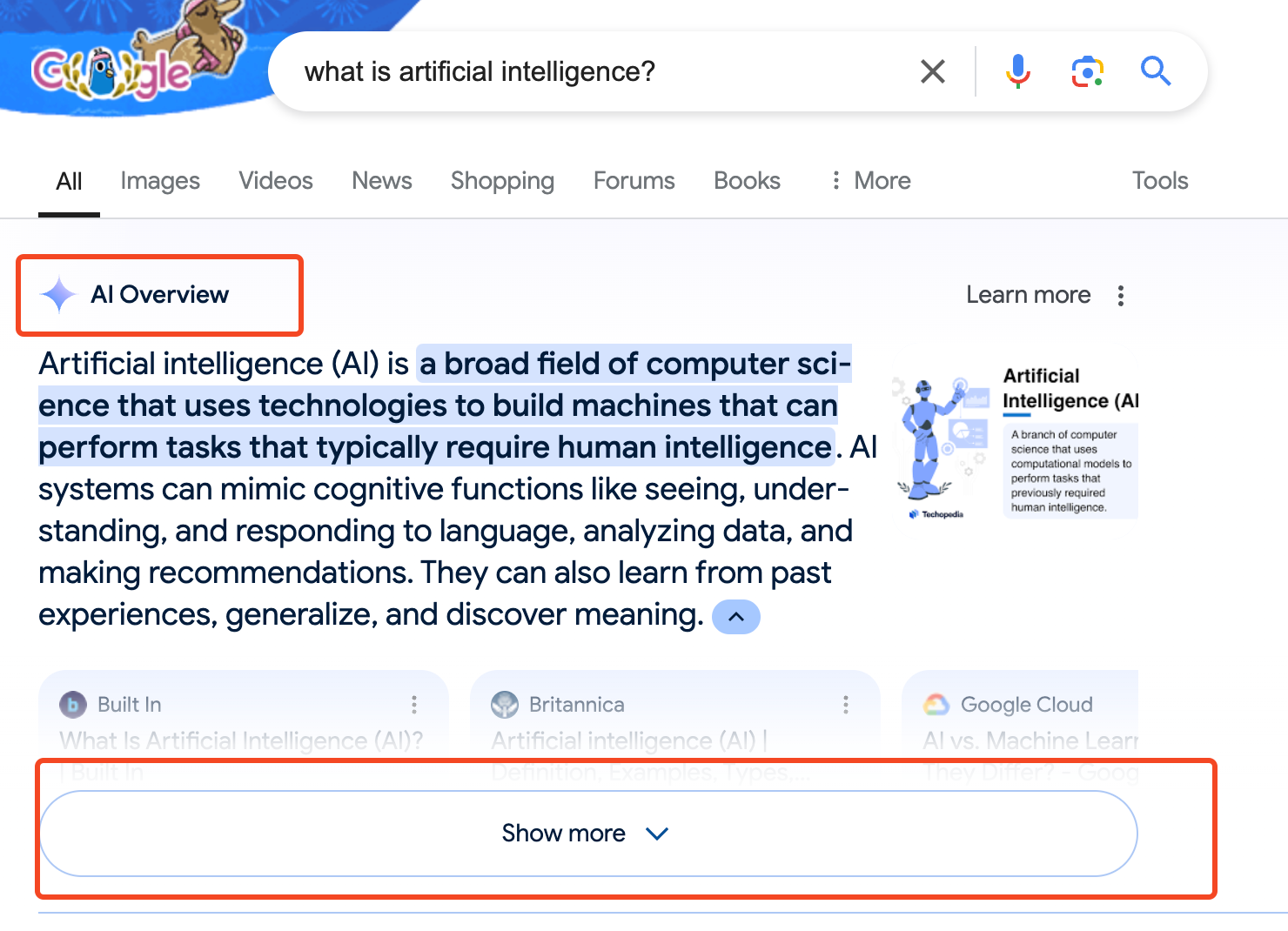
Starting the Loop for Search and Scrape
Now we are starting the loop to search and scrape.
If the driver is not able to search, then it will print “Cannot Search”. Else it will print the query number it is searching for.
After searching it will scrape the source.
If AI Overview is found,
Then it will click on the “Show More” button
Takes the screenshot and saves it to the given folder path
Append the Result to the result variable
Scrape links and append them to the all_links variable
Check if your domain name is available and then store the link to my_domain_link if available.
Now after 40 to 50 queries, Google is definetly going to block you. If it blocks you then the page will have the phrase “Our systems have detected unusual traffic”.
If Google blocks us, then we wait randomly for 5 to 7 minutes and try again.
If nothing is found then it will append “AI Overview Not Found” in the result variable.
#starting the loop
for i, j in zip(query_list, range(0, number_of_queries)):
try:
print('current_query_number: ' + str(j))
try:
search_bar_class = 'gLFyf'
search(url_to_visit, search_bar_class, i)
time.sleep(3)
except:
print('Cannot Search')
result.append('cannot search')
queries.append(i)
page_source = driver.page_source #scraping page source
#screenshot path and file name
screenshot_file_path = '/Users/username/Desktop/screenshots/' #replace with your path
screenshot_file_name = screenshot_file_path + i[:200] + '.png'
if search_term_0 in page_source:
try:
try:
click_button('ni04u') #show more button
except:
click_button('in7vHe') #show more button
scroll = 'window.scrollBy(0, 30)'
driver.execute_script(scroll)
time.sleep(1)
result.append('AI Overview Found')
print('AI Overview Found')
queries.append(i)
scrape_links('ibUR7b', i)
driver.save_screenshot(screenshot_file_name)
print('Screenshot saved')
except:
print('Some error even if AI Overview is found')
result.append('AI Overview Found')
queries.append(i)
all_links.append('Link Not Found')
my_domain_link.append('Link Not Found')
driver.save_screenshot(screenshot_file_name)
print('Screenshot Saved')
elif search_term_6 in page_source:
print('Google is Blocking')
result.append('Google Blocked')
queries.append(i)
driver.save_screenshot(screenshot_file_name)
time.sleep(random.randint(300,400))
else:
result.append('AI Overview Not Found')
queries.append(i)
driver.save_screenshot(screenshot_file_name)
print('Screenshot Saved')
time.sleep(random.randint(7,10))
except:
final_df = pd.DataFrame({'Query': queries, 'AI overview Status': result})
my_domain_links = pd.DataFrame(my_domain_link, columns=['My Domain Links'])
my_domain_links = my_domain_links.drop_duplicates(subset=['My Domain Links']).reset_index(drop=True)
all_links = pd.DataFrame(all_links, columns=['all_links'])
all_links = all_links.drop_duplicates(subset=['all_links']).reset_index(drop=True)Saving the Data to CSV File
Once the loop is completed, we will quit the browser and create Dataframes from the data we stored in our variables. And save the Dataframes to a CSV file.
You can also extend this script to upload these dataframes to Google Sheets using gpread and gspread_dataframe.
driver.quit()
final_df = pd.DataFrame({'Query': queries, 'AI overview Status': result})
my_domain_links = pd.DataFrame(my_domain_link, columns=['My Domain Links'])
my_domain_links= my_domain_links.drop_duplicates(subset=['My Domain Links']).reset_index(drop=True)
all_links = pd.DataFrame(all_links, columns=['all_links'])
all_links = all_links.drop_duplicates(subset=['all_links']).reset_index(drop=True)
print('SGE Output')
print(final_df)
print('My Domain Links')
print(my_domain_links)
print('All Links')
print(all_links)
final_df.to_csv(r'sge_output.csv',encoding='utf-8')
my_domain_links.to_csv(r'my_domain_links.csv',encoding='utf-8')
all_links.to_csv(r'all_links.csv', encoding='utf-8')Important Note: This script takes a lot of time to run because we cannot send too many concurrent requests to Google. So it is best to run it for like 200 to 300 queries which should take around 2 to 3 hours.
Somre Requirements before running the script -
You need to be on US IP Address. VPNs will work but not the ones which are browser extensios.
You should have Chrome Browser installed
Script will take few hours to run, so make sure your computer is active for longer time.
Following is the whole script -
from seleniumbase import Driver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import pandas as pd
import random
df = pd.read_csv(r'query_list.csv',encoding='latin-1')
df = df.replace("/"," ",regex=True)
print(df)
query_list = df['query'].values.tolist()
#test_queries
#query_list = ['what is digital marketing','features of macbook pro m3','write few lines about christmas','what are the properties of metal']
print(query_list[:5])
number_of_queries = len(query_list)
#path to chromedriver
driver = Driver(uc=True, headless=True)
#login to google manually
google_login_url = 'https://accounts.google.com/v3/signin/identifier?hl=en-gb&ifkv=AaSxoQyH1Qet0VlLGN7HL7CD1zRZkw0dVFB4bXApnkylfeDCW4kx3vmK9HBjvDjfi4a6yi3WFJJfug&flowName=GlifWebSignIn&flowEntry=ServiceLogin&dsh=S1544068279%3A1715766753444785&ddm=0'
#function to login to google
def login(email,password):
driver.get(google_login_url)
try:
current_url = driver.current_url
time.sleep(5)
# Find and fill in the email input field
email_input = driver.find_element("name", "identifier")
email_input.send_keys(email)
email_input.send_keys(Keys.RETURN)
print('Email Entered')
current_url = driver.current_url
print(f"Current URL: {current_url}")
time.sleep(5)
password_input = driver.find_element(By.NAME, 'Passwd')
password_input.send_keys(password)
password_input.send_keys(Keys.RETURN)
print('Password Entered')
current_url = driver.current_url
print(f"Current URL: {current_url}")
time.sleep(5)
except:
print('Not able to login')
driver.save_screenshot('<PATH TO YOUR FOLDER>/error.png')
#function to search
def search(url, class_name, search_term):
driver.get(url)
input_element = driver.find_element(By.CLASS_NAME, class_name)
input_element.send_keys(search_term, Keys.ENTER)
#function to click on any button
def click_button(class_name):
button = driver.find_element(By.CLASS_NAME, class_name)
button.click()
#function to scrape links
def scrape_links(class_name, query):
links = driver.find_elements(By.CLASS_NAME, class_name)
for j in links:
link = j.get_attribute('href')
query_link = query + '@' + link
all_links.append(query_link)
if 'my_domain_name' in link:
query_link = query + '@' + link
my_domain_link.append(query_link)
#declare variables to store the values
result = []
my_domain_link = []
all_links = []
queries = []
login('email_id','password') #replace with your email and password
url_to_visit = 'https://www.google.com/?gl=us&hl=en'
#search_terms
search_term_0 = 'AI Overview'
# search_term_1 = 'Generative AI is experimental'
# search_term_2 = 'AI overviews are experimental'
# search_term_3 = 'Get an AI Overview for this search?'
# search_term_4 = 'overview is not available for this search'
# search_term_5 = 'Try again later.'
search_term_6 = 'Our systems have detected unusual traffic'
#starting the loop
for i, j in zip(query_list, range(0, number_of_queries)):
try:
print('current_query_number: ' + str(j))
try:
search_bar_class = 'gLFyf'
search(url_to_visit, search_bar_class, i)
time.sleep(3)
except:
print('Cannot Search')
result.append('cannot search')
queries.append(i)
page_source = driver.page_source #scraping page source
#screenshot path and file name
screenshot_file_path = '/Users/username/Desktop/screenshots/' #replace with your path
screenshot_file_name = screenshot_file_path + i[:200] + '.png'
if search_term_0 in page_source:
try:
try:
click_button('ni04u') #show more button
except:
click_button('in7vHe') #show more button
scroll = 'window.scrollBy(0, 30)'
driver.execute_script(scroll)
time.sleep(1)
result.append('AI Overview Found')
print('AI Overview Found')
queries.append(i)
scrape_links('ibUR7b', i)
driver.save_screenshot(screenshot_file_name)
print('Screenshot saved')
except:
print('Some error even if AI Overview is found')
result.append('AI Overview Found')
queries.append(i)
all_links.append('Link Not Found')
my_domain_link.append('Link Not Found')
driver.save_screenshot(screenshot_file_name)
print('Screenshot Saved')
elif search_term_6 in page_source:
print('Google is Blocking')
result.append('Google Blocked')
queries.append(i)
driver.save_screenshot(screenshot_file_name)
time.sleep(random.randint(300,400))
else:
result.append('AI Overview Not Found')
queries.append(i)
driver.save_screenshot(screenshot_file_name)
print('Screenshot Saved')
time.sleep(random.randint(7,10))
except:
final_df = pd.DataFrame({'Query': queries, 'AI overview Status': result})
my_domain_links = pd.DataFrame(my_domain_link, columns=['My Domain Links'])
my_domain_links = my_domain_links.drop_duplicates(subset=['My Domain Links']).reset_index(drop=True)
all_links = pd.DataFrame(all_links, columns=['all_links'])
all_links = all_links.drop_duplicates(subset=['all_links']).reset_index(drop=True)
driver.quit()
final_df = pd.DataFrame({'Query': queries, 'AI overview Status': result})
my_domain_links = pd.DataFrame(my_domain_link, columns=['My Domain Links'])
my_domain_links= my_domain_links.drop_duplicates(subset=['My Domain Links']).reset_index(drop=True)
all_links = pd.DataFrame(all_links, columns=['all_links'])
all_links = all_links.drop_duplicates(subset=['all_links']).reset_index(drop=True)
print('SGE Output')
print(final_df)
print('My Domain Links')
print(my_domain_links)
print('All Links')
print(all_links)
final_df.to_csv(r'sge_output.csv',encoding='utf-8')
my_domain_links.to_csv(r'my_domain_links.csv',encoding='utf-8')
all_links.to_csv(r'all_links.csv', encoding='utf-8')
If you are facing any issues, feel free to contact me on Linkedin.