


How to check Similarity Score between Meta Title and H1 - Heading?
Analyze the similarity between Meta Title and Heading using Python

Imagine you clicked on the link with the text “Tips for writing SEO-friendly content” and when you land on the page, the big heading says “Best SEO Content Writing Tools”.
Now that is not a very good User experience.
Not only for you but also for Search Engine bots like Google.
It creates confusion for users and also for bots.
Hence, it is always a best practice to keep your Meta Titles and first Heading either similar or exactly the same.
But let’s say you have thousands or even millions of URLs on your website and you want to analyze the similarity percentage between Titles and Headings.
Because even if it is not exactly the same, it may be similar.
For example, “Tips for writing SEO-friendly content” and “SEO-Friendly content writing tips” are very similar.
Hence, it is not possible to find a Title-Heading mismatch by just using excel IF Formula (I wish it was though!).
But it is not as complicated as it looks. A simple python script can help us achieve this.
To keep it simple, I am going to take random 100 URLs from this website -
www.additudemag.com
You can grab the list of URLs here with Title and Heading.
We are going to use a python package called: fuzzywuzzy.
Fuzzywuzzy uses fuzzy logic to compare two texts and it gives a similarity score as an output.
Let’s install the required packages first -
pip install fuzzywuzzy
pip install pandas
pip install python-Levenshtein
Python-Levenshtein is an optional package to avoid warnings. In case you are facing issues installing this package on Windows, install it using its wheel file.
Now let’s jump right into the code -
Import required packages
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
import pandas as pd
The next step is to download the above Google sheet as a CSV and store it somewhere on your local storage.
Once we have the file ready, we will use them to create Panda Dataframes.
df = pd.read_csv(r'PATH TO CSV FILE')
Now that we have our data frame ready, let’s convert them to a list so that we can run them through a loop one by one.
headings = df['Heading'].values.tolist()
titles = df['Title'].values.tolist()
sim_score = [] #declaring a blank list to store similarity score values
The next step is to run a for loop on both lists and apply fuzzy logic to them.
for i,j in zip(headings, title):
sim_score.append(fuzz.ratio(i,j))
The above loop will feed the heading and title to the fuzzy logic and fill the sim_score list with the similarity score values.
Now we will merge the two data frames and store them in a CSV file.
similarity_score_df = pd.DataFrame(sim_score)similarity_score_df.columns = ['similarity_score']final_df = pd.concat([df, similarity_score_df], axis=1)
final_df.to_csv(r'Path to your output csv file')
Here is what the final output CSV file looks like -
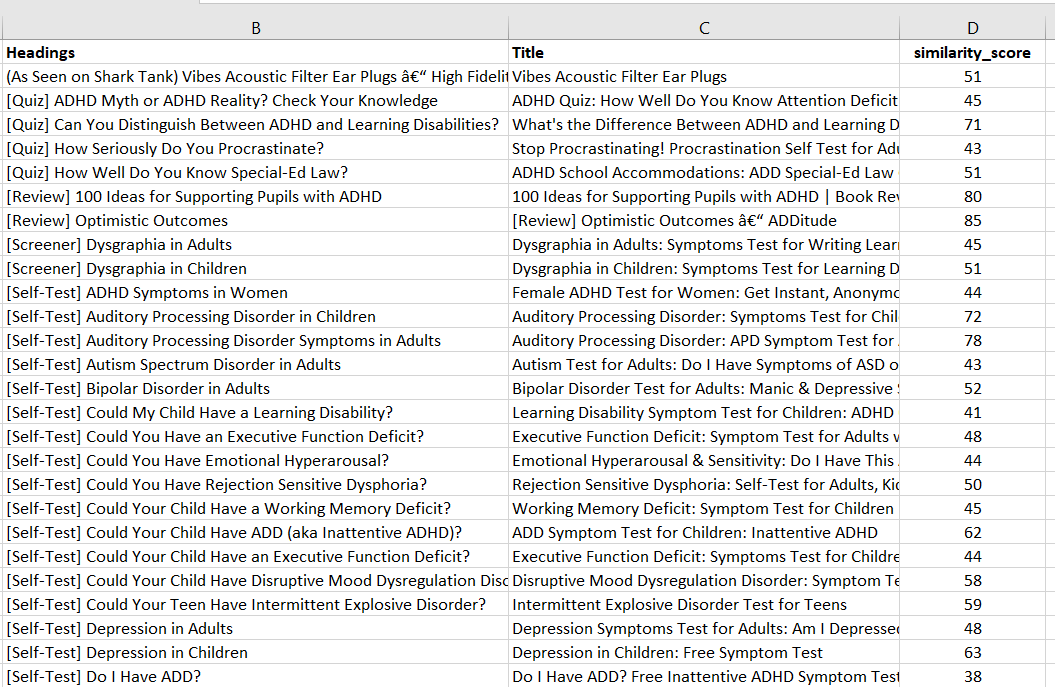
Full code below -
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
import pandas as pd
df = pd.read_csv(r'PATH TO CSV FILE')
headings = df['Heading'].values.tolist()
titles = df['Title'].values.tolist()
sim_score = []
for i,j in zip(headings, titles):
sim_score.append(fuzz.ratio(i,j))
similarity_score_df = pd.DataFrame(sim_score)
similarity_score_df.columns = ['similarity_score']
final_df = pd.concat([df, similarity_score_df], axis=1)
final_df.to_csv(r'PATH TO OUTPUT FILE')Thanks for reading!
Sharing is caring
Tweet if facing any issues: @stanabk